이번에는 Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models(Mengsong Wu et al., 2025) 라는 논문을 리뷰해보고자 합니다. 이 논문을 리뷰하고자 할 때, 블로그 제목을 어떻게 해야할지 고민하다가 이 부분은 그냥 GPT 한테 물어봤습니다!! 그랬더니 '언어 모델의 숨은 무기, Chain-of-Tools로 깨우다' 라는 제목을 추천해주더군요. 왜 이런 제목을 추천하는지 이제 리뷰를 해보도록 하죠.
Tool learning can further broaden the usage scenarios of large language models (LLMs). However most of the existing methods either need to finetune that the model can only use tools seen in the training data, or add tool demonstrations into the prompt with lower efficiency. In this paper, we present a new Tool Learning method Chain-of-Tools. It makes full use of the powerful semantic representation capability of frozen LLMs to finish tool calling in CoT reasoning with a huge and flexible tool pool which may contain unseen tools. Especially, to validate the effectiveness of our approach in the massive unseen tool scenario, we construct a new dataset SimpleToolQuestions. We conduct experiments on two numerical reasoning benchmarks (GSM8K-XL and FuncQA) and two knowledge-based question answering benchmarks (KAMEL and SimpleToolQuestions). Experimental results show that our approach performs better than the baseline. We also identify dimensions of the model output that are critical in tool selection, enhancing the model interpretability. Our code and data are available at: https://github.com/ fairyshine/Chain-of-Tools
도구 학습은 대형 언어 모델(LLMs)의 활용 가능성을 더욱 넓힐 수 있습니다. 그러나 기존 방법들은 대부분 모델을 미세조정하여 학습 데이터에 등장한 도구만 사용할 수 있도록 하거나, 비효율적으로 도구 시연을 프롬프트에 추가합니다. 본 논문에서는 새로운 도구 학습 방법인 Chain-of-Tools를 제시합니다. 이 방법은 동결된 언어 모델의 강력한 의미 표현 능력을 최대한 활용해, CoT 추론 과정에서 미사용 도구를 포함한 거대한 유연한 도구 풀을 사용하여 도구 호출을 수행합니다. 특히, 대규모 미사용 도구 시나리오에서 접근법의 효과를 검증하기 위해 새로운 데이터셋 SimpleToolQuestions를 구축하였습니다. GSM8K-XL과 FuncQA라는 두 개의 숫자 추론 벤치마크, 그리고 KAMEL과 SimpleToolQuestions라는 두 개의 지식 기반 질의 응답 벤치마크에서 실험한 결과, 제안한 방법이 기준 방법보다 우수한 성능을 보였습니다. 또한, 모델 출력의 중요한 차원을 식별해 도구 선택 과정의 해석 가능성을 높였습니다. 코드와 데이터는 https://github.com/fairyshine/Chain-of-Tools 에서 확인할 수 있습니다.
이 논문의 초록은 위와 같은데, 이를 요약해보자면 이 논문은 동결된 대형 언어 모델이 학습 데이터에 없던 미사용 도구도 활용할 수 있도록 하는 Chain-of-Tools 방법을 소개한다고 합니다. 기존 미세조정이나 낮은 효율의 도구 시연 대신, 모델의 강력한 의미 표현 능력을 이용해 방대한 도구 풀에서 도구를 호출함으로써 효율성을 높입니다. 제안한 방법은 숫자 추론과 지식 기반 질의 응답 벤치마크에서 기존 방법보다 우수한 성능을 보였으며, 도구 선택에 중요한 모델 출력 요소를 파악해 해석 가능성을 향상시켰습니다. 여기서 도구가 무엇을 의미하는지 읽으면서도 궁금했는데 한번 더 가보도록 합시다.

이 논문은 대형 언어 모델(LLM) 에이전트가 특정 작업(예: 수학 계산, 그림 그리기 등)을 수행할 때 외부 도구를 활용하도록 하는 새로운 미세조정 기반 도구 학습 방법인 Chain-of-Tools(CoTools)를 소개한다고 합니다. 여기서 도구의 의미가 등장하는데 여기서 '도구'는 날씨 정보, 계산기 등 LLM이 자체적으로 처리하기 어려운 작업을 대신해주는 외부 응용 프로그램이나 API를 의미한다고 합니다. CoTools는 LLM의 추론 과정인 CoT 내에서 은닉 상태를 활용하여 적절한 도구를 실시간으로 선택하고 호출하며, 미사용 도구까지 포함하는 방대한 도구 풀을 효과적으로 관리할 수 있다는데요. 이것만 들으면 MCP와 굉장히 유사한 것 같은데 어떤 차이가 있는지 계속 읽어보도록 하겠습니다. 실험 결과, 제안된 방법은 숫자 추론 및 지식 기반 질문 응답 벤치마크에서 기존 방법보다 우수한 성능을 보였으며, 도구 선택 과정에서 중요한 은닉 상태 차원을 밝혀내어 모델 해석 가능성도 강화하였다고 합니다.
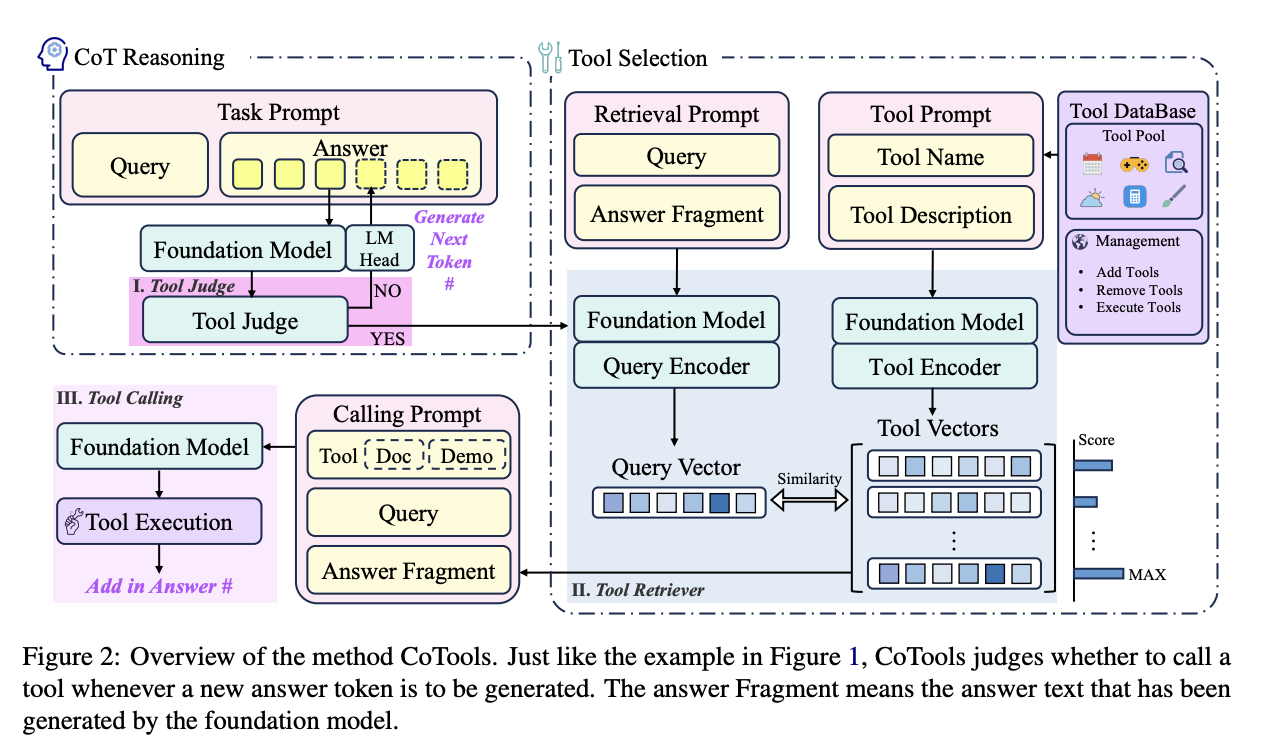

CoTools를 구성하는 방법을 구체적으로 서술하면 다음과 같습니다. Chain-of-Tools(CoTools)는 동결된 언어 모델의 은닉 상태 정보를 활용해 어느 순간에 외부 도구를 호출하고, 어떤 도구를 선택할지를 결정하는 미세조정 기반 도구 학습 방법입니다. 전체 시스템은 크게 세 구성 요소로 나뉘는데, 첫째는 답변 생성 과정 중 특정 토큰의 은닉 상태를 기반으로 도구 호출 여부를 판단하는 도구 판단기(Tool Judge)이며, 이는 현재 토큰의 은닉 상태를 입력받아 0과 1 사이의 점수를 산출하고, 이 값이 임계치보다 높으면 도구 호출을 시도합니다. 둘째는 도구 검색기(Tool Retriever)로, 질의 인코더와 도구 인코더를 사용하여 답변 단편에서 도출한 질의 벡터와 미리 준비된 도구 벡터 간의 유사도를 계산해 가장 적합한 도구를 선택합니다. 마지막으로 선택된 도구는 프롬프트 형식으로 파라미터 값을 생성한 후 호출되어 그 결과가 최종 답변에 반영됩니다. 이러한 구조 덕분에 CoTools는 기존에 학습 데이터에 포함되지 않은 미사용 도구까지도 활용할 수 있으며, 실험에서는 산술 문제 해결(GSM8K-XL, FuncQA) 및 지식 기반 질문 응답(KAMEL, STQuestions)에서 기존 방법보다 우수한 성능과 일반화 능력을 보여주었습니다. 그림 2과 그림 3에서 전체 절차와 각 구성 요소의 역할을 자세히 설명하며, 은닉 상태의 특정 차원이 도구 선택에 중요한 역할을 한다는 사실도 확인되어 모델의 해석 가능성을 높이는 추가적인 인사이트를 제공하였습니다고 합니다.
여기서, MCP와 큰 차이점이 하나 발견되는 것 같은데요. 은닉 상태 정보를 활용한다는 점인데, 이에 대해서 더욱 자세히 기술해보자면 CoTools에서는 도구 선택에 있어서 언어 모델이 내부에서 생성하는 은닉 상태(즉, 입력을 처리하며 만들어지는 수치적 표현)를 그대로 사용하는 대신, 그 중 도구 선택에 중요한 정보를 담고 있는 특정 차원들만 골라내어 재구성합니다. 언어 모델의 은닉 상태는 문맥, 의미, 그리고 다양한 정보를 포괄적으로 포함하지만, 모든 차원이 도구 선택에 직접적으로 도움이 되는 것은 아닙니다. 따라서, 불필요한 정보를 걸러내고 도구 선택과 관련된 핵심적인 특징들을 부각하기 위해, 추가적인 신경망 계층을 사용하여 특정 차원들을 재조합합니다.
좀 더 구체적으로 설명하자면, 먼저 은닉 상태에서 게이트 메커니즘과 선형 변환을 적용하여, 모델이 도구를 호출할 때 중요한 역할을 하는 정보(예를 들어, 현재 질의나 답변 단편과 관련된 맥락)를 추출합니다. 이 과정에서는 원래의 은닉 상태에 오프셋을 추가하고, 이를 다시 통합한 후 정규화하는 과정을 거쳐 최종적인 벡터(질의 벡터 또는 도구 벡터)를 생성합니다. 이 벡터는 도구 선택에 특화된 정보를 담도록 학습되며, 생성된 질의 벡터와 각 도구의 벡터 간 내적을 통해 유사도를 계산함으로써, 가장 적합한 도구를 선택할 수 있게 됩니다.
은닉 차원을 활용하는 이유는 크게 두 가지입니다. 첫째, 은닉 상태에는 방대한 정보가 내포되어 있어 그 중 도구 호출에 직접적인 영향을 미치는 핵심 정보를 추출함으로써, 보다 정확하게 상황에 맞는 도구를 선택할 수 있습니다. 둘째, 불필요한 정보가 제거되면 모델이 도구 선택 시 계산해야 하는 복잡성이 줄어들어, 효율성과 해석 가능성이 향상됩니다. 즉, 이러한 방식은 모델의 기존 표현 능력을 최대한 활용하면서도 도구 호출의 정확도와 속도를 개선하는 효과적인 방법입니다.
이제 이 방법론을 적용하고 실험을 해본 결과를 소개드리고자 하는데 먼저, 숫자 추론 작업에서는 기존 ToolkenGPT에서 만든 GSM8K-XL과 FuncQA 데이터셋을 사용해 기본 산술 연산(+, −, ×, ÷) 및 13종의 산술 도구를 활용한 문제 해결을 평가하며, 답변의 최종 결과 정확도를 기준으로 성능을 측정합니다.
반면, 지식 기반 질문 응답(KBQA) 작업에서는 KAMEL 데이터셋과 도구의 종류가 매우 많은 SimpleToolQuestions(STQuestions) 데이터셋을 사용하여, 모델이 질문의 의미를 이해하고 관련 도구를 올바르게 선택하는 능력을 평가합니다. STQuestions는 학습 데이터에 등장하는 도구 999개와 테스트에서만 등장하는 미사용 도구 837개를 포함하여, 대규모 도구 풀에서의 선택 정확도를 중점적으로 분석합니다.
실험 결과, CoTools는 숫자 추론 벤치마크에서는 LLaMA2-7B 및 Mistral 기반에서 기존의 0-shot ChatGPT나 ToolkenGPT와 비교해 우수한 성능을 보였으며, 특히 Mistral 기반의 경우 눈에 띄는 성능 향상이 확인되었습니다. KBQA 벤치마크에서는 KAMEL과 STQuestions에서 CoTools가 ToolkenGPT보다 높은 도구 선택 정확도를 기록하였으며, 미사용 도구 처리에서도 CoTools가 우수한 성능을 나타내어, 도구 설명을 효과적으로 활용해 새로운 도구에 일반화할 수 있음을 보여주었습니다.
또한, 데이터 품질이 높은 경우(KAMEL(sup))와 합성 데이터(KAMEL(syn))를 비교한 결과, 합성 데이터에서는 CoTools가 ToolkenGPT보다 20% 이상 더 높은 성능을 보였고, 도구의 수가 증가하는 상황에서도 CoTools는 약 10% 이상의 높은 선택 정확도를 유지하였습니다. 마지막으로, Query 인코더와 도구 인코더가 공유하는 Wdim 파라미터를 분석한 결과, 학습률에 따라 은닉 상태의 특정 차원이 크게 변화하며 이들 차원이 도구 선택에 중요한 역할을 하는 것으로 나타났습니다.
전체적으로, 본 연구는 CoTools가 다양한 벤치마크에서 기존의 방법보다 우수한 도구 선택 성능과 일반화 능력을 보이며, 대규모 및 미사용 도구 상황에서도 효과적으로 작동한다는 것을 실험과 분석을 통해 입증하였습니다.
이를 최종적으로 정리하는 Conclusion 내용은 다음과 같습니다. 본 논문은 동결된 대형 언어 모델을 기반으로 CoT(Chain-of-Thought) 도구 학습 방법인 CoTools를 제안합니다. CoTools는 답변 생성 과정 중 도구 호출을 통합하여, 기초 모델의 일반화 능력을 유지하면서도 효과적으로 적절한 도구를 선택할 수 있도록 합니다. 실험 결과, 숫자 추론과 지식 기반 질문 응답(KBQA) 벤치마크에서 기존 기법에 비해 도구 선택 능력이 크게 개선되었으며, 은닉 상태의 특정 차원이 도구 선택 과정에 미치는 역할을 분석하여 모델의 해석 가능성을 높였습니다. 이와 같은 방법론은 실세계 응용에 유용하며, 향후 도구 학습 분야의 발전에 기여할 수 있을 것으로 기대됩니다.
이 논문은 CoT를 위한 방법론(?)이라 하지만 제가 보았을 때 MCP와 유사하게 LLM이 외부 도구에 효율적으로 접근할 수 있도록 하는 방법론에 가까워 보입니다. 특히, 은닉 상태를 활용한다는 것이 매우 흥미로웠습니다.
'AI > LLM' 카테고리의 다른 글
| LLM도 '브레인 롯(Brain Rot)'에 걸릴 수 있을까? (0) | 2025.10.20 |
|---|---|
| Efficient Memory Management for Large Language Model Serving with PagedAttention (0) | 2025.09.03 |
| Reasoning Models Don’t Always Say What They Think (0) | 2025.04.12 |
| Overtrained Language Models Are Harder to Fine-Tune (과잉 훈련 재앙) (0) | 2025.04.05 |
| 추론 모델을 구현해보자! (0) | 2025.03.22 |